○Data Type, Structure
▶Numeric value
▷double (기본): 소수 (1.0 ...)
▷Integer: 정수 (1L, 2L ...)
▷Complex: 복소수 (5 + 3i)
▷Character: 문자(열) ("a" "Statistics")
▶Vectors
▷R에서 자주 사용되는 데이터 집합.
▷하나의 데이터 타입에 대해서만 담을 수 있음. (여러개 -> 자동으로 하나로 통합)
▶생성
▷x = c(1, 2, 3 ...) : c() 함수 (combine), Datas, Vectors를 합쳐줌.
▷y = 1:100 : Sequence로 생성 (1~100까지의 Vector)
▷z = seq(from = 1.5, to = 4.2, by = 0.1 : 간격을 지정하여 Sequence 생성 (from 부터 to 까지 by 간격으로)
▷ = seq(1.5, 4.2, 0.1) : from, to, by 을 생략가능
▷r = rep("A", times = 10) : 하나의 data를 반복해서 생성.
▶접근
▷v[3] : 3번째 element (0부터 시작이 아닌, 1부터 시작임에 주의)
▷v[-2] : 끝에서 2번째 element
▷v[1:3] : 1~3 번째 element가 있는 subvector
▷v[c(1,3,4)] : 1, 3, 4 번째 element가 있는 subvector
▷z = c(TRUE, TRUE, FALSE, TRUE, TRUE, FALSE)
x[z] : TRUE인 index의 element들 (1, 2, 4, 5번째)
▷y[y>3] : 3보다 큰 모든 element들
▶함수
▷length(vector) : vector의 길이
▷rev(vector) : 해당 vector의 역순
▶연산
▷vector에 대해 +, -, *, ^ ... 등의 연산을 하면, vector의 모든 element에 대해 해당 연산을 진행한다.
▶Matrix
▷행렬을 표현 가능
▷Vector -> Matrix로의 변환을 주로 사용한다.
▶생성 (test_mat = 1:9)
▷x_matrix = matrix(test_mat, nrow = 3, ncol = 3) : Vector를 Column순으로 Matrix로 만든다.
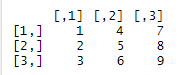
▷y_matrix = matrix(test_mat, nrow = 3, ncol = 3, byrow = true) : Vector를 row순으로 Matrix로 만든다.
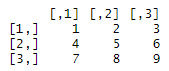
▷z_matrix = matrix(0, 2, 4) : 0으로 차있는 2행 4열의 Matrix
▷rbind (test_mat, rev(test_mat), rep(1,9) ) : row(Vector)들을 묶어 Matrix를 만든다.
▷cbind (col_1 = test_mat, col_2 = rev(test_mat), col_3 =rep(1,9) ) : column(Vector)들을 묶어 Matrix를 만든다.
▶접근
▷x_matrix [1,2] : 1행 2열의 요소에 접근
▷x_matrix [,2] : 2열의 요소들에 접근 (Vector형태)
▷x_matrix [2, c(1, 3)] : 2행 1, 3열의 요소에 접근
▶함수
▷dim(mat) : matrix의 dimension ([1]: row, [2]: column)
▷rowSums(mat) : 각 행의 합의 vector
▷colSums(mat) : 각 열의 합의 vector
▷rowMeans(mat) : 각 행의 평균값 vector
▷colMeans(mat) : 각 열의 평균값 vector
▷diag(mat) : Matrix의 diagonal element들의 vector
▷diag(int n) : n×n의 identity matrix
▷crossprod(x_mat, y_mat) : 두 벡터의 내적
▶연산
▷Matrix에 대해 +, -, *, / 등의 연산을 하면 모든 element에 대해 해당 연산을 수행한다.
▷Matrix끼리는 같은 크기의 Matrix에 대해서만 +, -, *, /를 지원한다?
▶Matrix Multiplication
▷x_mat%*%y_mat
▶List
▷여러 개의 데이터를 저장하는 데이터 집합.
▷여러 데이터 타입들을 한 번에 담을 수 있음.
▶생성
▷x = list(42, "Hello", TRUE)
▷ex_list=list(
a = c(1,2,3,4),
b = TRUE,
c = "Hello!",
d = function(arg=42) {print("Hello World")},
e = diag(5) )
▷name - value의 짝을 넣을 수 있음.
▶접근 (위의 ex_list에 대해)
▷ex_list[1] : 첫번째 name-value의 짝
▷ex_list[1:2] : 1, 2번째 name-value의 짝
▷ex-list[[1]] : 첫번재 value
▷ex_list$e = ex_list[["e"]] : name에 맞는 value
▷ex_list$d(arg=1) : element중 함수에 매개 변수를 주고 접근 가능.
○Data Frame
▷정보를 저장하여, 표(Table)의 형태로 나타낼 수 있는 자료구조
▶생성
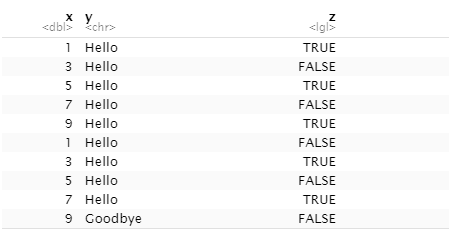
▷example_data = data.frame(x = rep(c(1,3,5,7,9),2),
y = c(rep("Hello",9),"Goodbye"),
z = rep(c(TRUE, FALSE), 5)
▷입력되는 모든 데이터는 Vector여야 하고, 크기가 같아야 한다.
▶접근
▷frame$x : name이 x인 vector
▷frame[row, column] : 해당 row, column의 값을 가져옴
▷frame[, column] : 해당 column의 값들 (Vector)
▷frame[row, ] : 해당 row
▷frame %>% filter (조건) %>% select (columnName1, ...)
▷조건을 만족하는, select columns로 이루어진 subset 생성
▷dplyr 라이브러리를 추가해야 사용 가능
▶함수
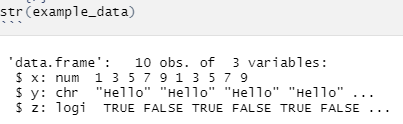
▷str(frame) : 해당 frame의 data structure를 보여줌
▷names(frame) : 해당 Data frame의 name들의 Vector
▷nrow(frame): row 수
▷ncol(frame) : column 수
▷dim(frame) : row column 수
▷subset(frame, ... ) : 해당 frame으로 subset을 만든다.
▷subset = 조건 : 해당 조건을 만족 ex) columnName > n
▷select = c("columnName1", ... ) : 해당 column들만 출력




